Работа с большими списками (файлами)
-
Здравствуйте.
Есть большие файлы 500К и более строк - при "Файл в список" и "Ресурс в список" - зависает напрочь :(
Можно ли\Как положить в список не весь файл, а например первые 1К строк?
Когда эти строки закончились - взять след. 1К и т.д.
-
@lirik В команде "Читать файл" есть выбор первого и последнего байта
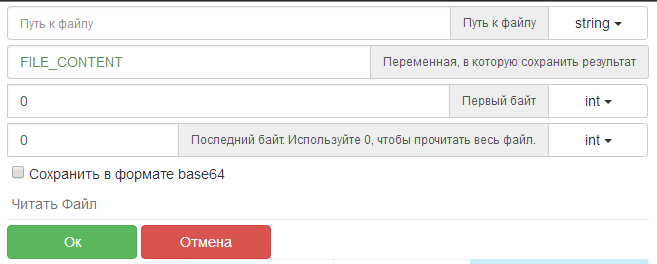
используйте как угодно. Можно сделать функцию, в ней цикл выбора 500к, а в скрипте условие, выбора следующих 500к.
-
@Fox Спасибо. Пробовал так, но я же не знаю сколько "байт" будет. Можно было бы брать и 1 (допустим певую) строку, но их длина отличается. Т.е. если в файле есть список например:
00cats_ru 00ekb 00element00 00far.cry3 00g_o_d_l_i_k_e00 00ham1 00id17009256686 00karandash00 00l0l 00ladynatali777 00luxury00 00margo00 00mdkто я не могу указать конкретное число "Последний байт", т.к. у каждой строки разное кол-во.
Попробовал брать регуляркой
^.*$берёт то что надо, но вот вопрос как теперь удалить эту строку из "FILE_CONTENT" ?
Оно ведь не кладёт каждую строку в массив, а всё в 1 переменнуюFILE_CONTENT: "00g_o_d_l_i_k_e00 00margo00 00o00o0o0o00o00 00princess 00rub 00rules 00thenewworld00 00xam..."
-
@lirik может проще будет разбить этот большой файл, на более мелкие по n количество строк, например с помощью KeyWordKeeper , и задать маску имени файла 1.txt, 2.txt и.т.д. И в цикле for потом пробегаемся по каждому файлику.
for 1 до n: применяем действие Читать файл или Читать файл в список указав в качестве пути C:/path/[[CYCLE_INDEX]].txtСкачать KeyWordKeeper : http://www.rusdocs.com/razrezat-tekstovyj-fajl-txt-na-chasti-ili-po-strokam
-
@santilo На самом деле так и делаю :) Но это жеж не феншуй совсем :(
Наверняка должен быть способ сделать без "лишних манипуляций"
Короче вот такое решение получается:- "Читать файл" - получаем переменную со списком
- Регуляркой берём строку
- "Заменить Строку" - заменяем на "ни что" (пустоту)
- есть ещё 1 проблема - как удалить пустую строку. Наверно javascript-ом, но я не умею :( Подскажите кто-то плз.
- "Сохранить файл"
-
@lirik сейчас можно сделать так, сложновато правда. Нужно в цикле читать по байтно файл до символа перевода строки, как только его встретили - собирать в строку. Правда не знаю, возможно в стандартном действии этот файл автоматически заменяется, то есть посмотреть на него нельзя будет, но нужно тестировать.
Как вариант - перенесите Ваш список в базу, тогда нагрузка точно упадет.
-
Варик с базой норм., но есть проблемка :( Этот файл заполняет другой проект. Т.е.
Проект 1 (парсер) заполняет файл baza.txt
Проект 2 (обработчик) берёт строку из файла baza.txt и "мандражирует" с ней :)
И всё это онлайн.
Проект 1 (парсер) заполняет файл baza.txt не построчно, а сразу неск. значений (массив) 5-10 - т.е. заливать в базу построчно "Вставить Запись" тоже не очень
@DrPrime а подскажи ПЛЗ как удалить пустую строку? Наверняка знаешь :) Что-то типо trim() или ещё как-тоFILE_CONTENT: " 00o00o0o0o00o00 00princess 00rub 00rules 00thenewworld00 00xam..."
-
@lirik спарси в список переменную по символу переводк строки \n вроде, удали по значению
-
@lirik Если так принципиально именно разбить, то можно с помощью командной строки..
Запустить процессsetlocal enabledelayedexpansion set q=0 set N=100 for /F "delims= " %%i in (file.txt) do ( set /a q+=1 if !q! GTR !N! set /a N+=100 @echo %%i >> file!N!.txt )file.txt имя файла
цифра 100 это количество строк на которое разбивать файл (меняется в двух местах).

