Page Html doesn't retrieve the HEAD of the page
-
I've added a few things to the tutorial GoogleParse. In the function "ParseGoogle" I wanted to visit every link and to get the TITLE (located in the HEAD of the html) of the page opened and then get back to page of results.
Here is the bottom part of my function (similar to the one of the tutorial except I save everything of file and I've added a click on each page results + parse of the TITLE) :
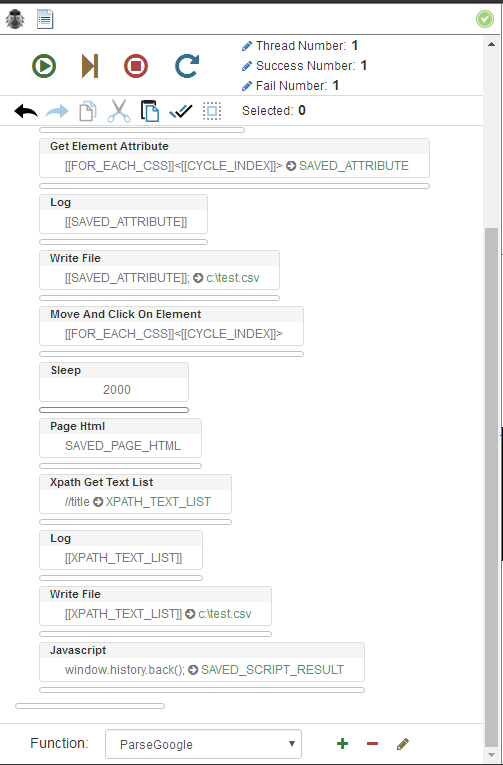
Start loop
Get element text (title of link on results)
Log
Write file ( appending to csv)
Get element attribute (href of link)
Log
Write file ( appending to same csv)
Move and Click on element (clicking results)
Sleep
Page html
Xpath Get Text List ( //title to get the title of the page)
Log
Write File ( appending to same csv)
Javascript (to get back to results page)When I try to get "Page html", it doesn't save the entire HTML document but only the body ! The variable inspector shows me only the body of the page and not the content of HEAD.
How can I retrieve the TITLE located in the HEAD of a page then ?
-
-
@TravelGreg2 to get element title you need to use "Get Element Text" action together with param.
Here is example:
0_1483528466704_GetTitle.xml